前言
虽说我是搞NLP的,但是老实说,这些基础的Seq2Seq模型我也没有仔细思考过。
序列到序列模型引入
自然语言是以序列表示的。和普通的点到点任务(比如加法器)不同,自然语言的序列,每个元素之间是有关系的。什么意思?
比如这句话:“我是一个学生”,其中“我”和“学生”显然是相关的,“是”表达了一个关系,表达的是“我”和“学生”之间的关系。为了处理这种元素彼此之间有依赖性的格式,相比于使用单纯的神经元层拼接,不得不想出一种新的模型架构。这种架构需要满足几个条件:
- 能够捕捉到序列之间的关系。
- 能够接受变长输入与输出。
第一点很好理解,第二点需要解释一下。在语言处理领域,这一点无比重要,因为语言是变长的,所以需要能够接受变长输入。除此之外,输出也要满足可变长性。那么为什么需要一个“新的”模型架构呢?因为传统的模型拼接,往往每一层的参数是确定的,输出层的参数也是确定的,这并不利于处理序列信息。
这便是序列到序列任务。
直觉的一闪:RNN
对于字符串的处理,容易想到的一个算法便是“滑窗算法”,这个算法常用于寻找字符串的重复元素。
没有错!序列是变长的,但是,我们可以将序列拆成等长的小块,然后进行分块处理。处理完每一个小块后,输出两个东西,一个是呈现给用户的、作为结果的输出;另一个是传递给下一时间步,处理下一个小块的信息。
那么,既然输入是定长的,就可以依靠传统的模型进行处理啦!
这便是最基本的RNN(循环神经网络)的思想,其架构图如下:
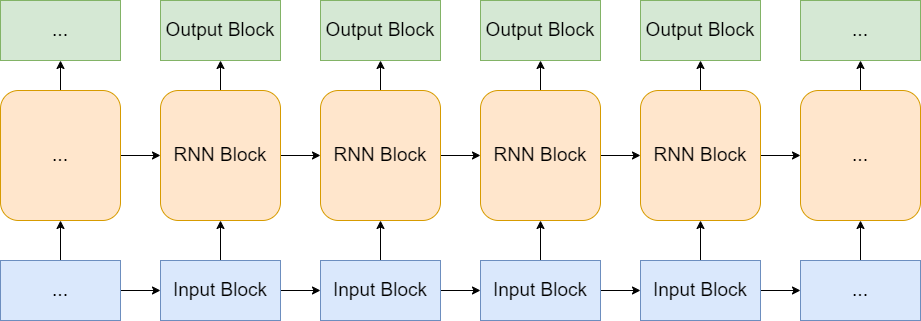
RNN块内部的结构为:
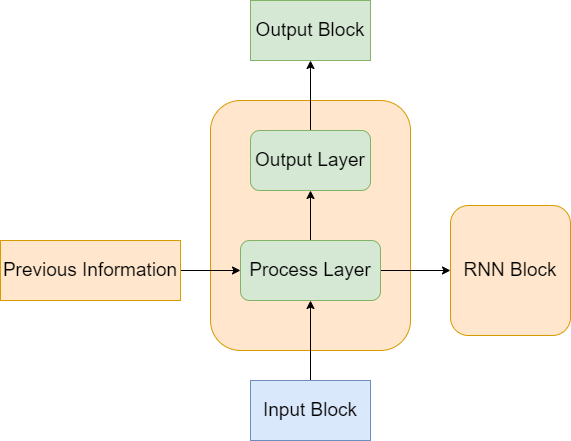
值得注意的是,RNN是应用同一个RNN模块对序列进行处理,从而获得整个序列的信息,这表明,只有一套参数。
RNN Block的公式可以表达为:
$$ \text{Process}(\mathbf{I},\mathbf{P})=f(\mathbf{W}_1\mathbf{I}+\mathbf{W}_2\mathbf{P}+\mathbf{B}_1) $$
$$ \text{Output}(\mathbf{I},\mathbf{P})=g(\mathbf{W}_3\text{Process}(\mathbf{I}, \mathbf{P})+\mathbf{B}_2) $$
那么,我们来看看RNN的梯度该如何计算,以Process Layer的权重举例子:
$$ \frac{\partial L}{\partial \mathbf{W}_2}=\frac{\partial L}{\partial f}\frac{\partial f}{\partial \mathbf{W}_2} $$
这个时候,需要注意:
$$ \frac{\partial f}{\partial \mathbf{W}_2} = \frac{\partial f}{\partial \mathbf{W}_2\mathbf{P}}\frac{\partial \mathbf{W}_2\mathbf{P}}{\partial \mathbf{W}_2} $$
其中,由于RNN是一个时序模型,所以:
$$ \frac{\partial \mathbf{W}_2\mathbf{P}}{\partial \mathbf{W}_2}=\mathbf{P}+\mathbf{W}_2\frac{\partial \mathbf{P}}{\partial \mathbf{W}_2} $$
这就完了吗?并没有!因为:
$$ \frac{\partial \mathbf{P}}{\partial \mathbf{W}_2} = \frac{\partial \mathbf{P}}{\partial \mathbf{P}_{-1}}\frac{\partial \mathbf{P}_{-1}}{\partial \mathbf{W}_2} $$
其中,$\mathbf{P}_{-1}$是指上一个时间步的Process Layer结果。从这个公式可以看出来,梯度计算的结果,和之前所有的状态都有关。如果$\frac{\partial \mathbf{P}}{\partial \mathbf{P}_{-1}}$为一个大于1的数,那么会造成梯度的指数级增加,如果小于1,就会造成指数级减小,因为:
$$ \lim_{x\to \infty}1.1^x=\infty $$
$$ \lim_{x\to\infty}0.9^x=0 $$
这便是RNN的梯度爆炸和梯度消失现象,这两个现象注定了RNN对于长序列的处理是有问题的。
不过,我们也可以用一些方法缓解这个问题,我们通常应用:
$$ f(x)=\tanh(x) $$
假设发生了梯度爆炸,那么:
$$ \frac{\partial \text{Process}}{\partial \text{Process}_{-1}} = (1-\text{Process}^2)\mathbf{W}_2 $$
值得注意的是,当$\mathbf{W}_{2}$很大的时候,根据$\tanh$函数的性质,上面这个式子反而很小,反之亦然,这就在一定程度上避免了RNN的梯度爆炸和梯度消失现象。
一点改进:LSTM
为了改进这两个问题,研究者们研究出了一个新的架构——LSTM,其结构如下:
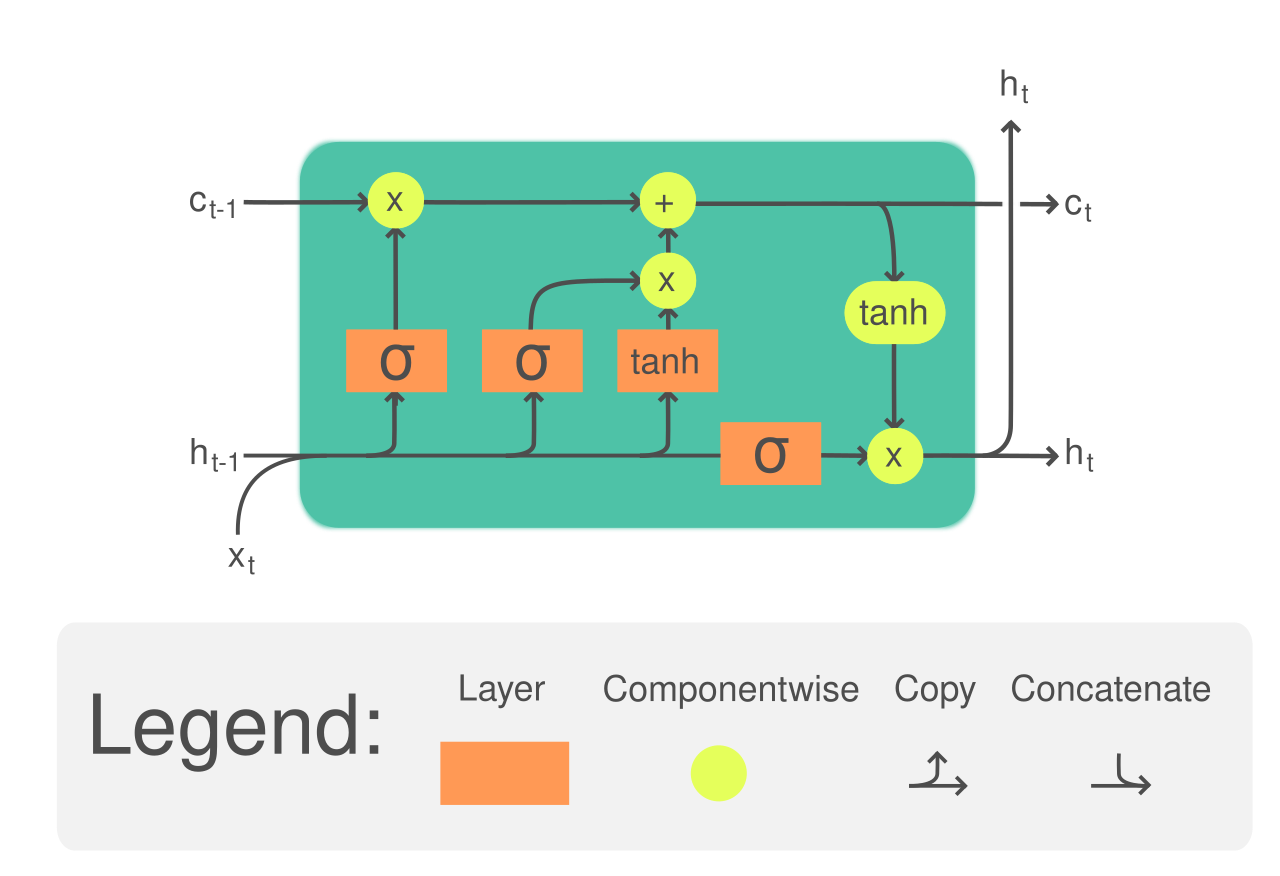
这是一个比较复杂的结构,其公式为:
$$ f_t=\sigma(\mathbf{W}_fx_t+\mathbf{U}_fh_{t-1}) $$
$$ i_t=\sigma(\mathbf{W}_ix_t+\mathbf{U}_ih_{t-1}) $$
$$ o_t = \sigma(\mathbf{W}_ox_t+\mathbf{U}_oh_{t-1}) $$
$$ \hat{c}_t = \tanh(\mathbf{W}_cx_t+\mathbf{U}_ch_{t-1}) $$
$$ c_t=f_t\circ c_{t-1}+i_t \circ \hat{c}_t $$
$$ h_t=o_t\circ \tanh(c_t) $$
其中,$f_t,i_t,o_t$我们称作遗忘门、输入门和输出门。我们关注于对前面信息的处理:
$$ \frac{\partial c_t}{\partial c_{t-1}}=f_t+c_{t-1}\frac{\partial f_t}{\partial c_{t-1}}+\hat{c}_t\frac{\partial i_t}{\partial c_{t-1}}+i_t\frac{\partial \hat{c}_t}{\partial c_{t-1}} $$
我们知道,$\tanh$和$\text{Sigmoid}$函数的求导格式差不多,都能满足梯度很大时,削弱影响。
统一的问题
这种模型由于需要循环处理,所以没有办法进行并行计算,也就难以应用GPU进行优化。