前言
这个系列的文章,旨在记录我对破解的理解、经验与思考。
所谓破解,就是通过改变程序的运行机制与逻辑,来达到自己想要的目的。
为了达到这个目标,首要的知识便是,程序是如何运行的?为了简单,我们这次就使用一个最简单的C语言程序test.c:
#include <stdio.h>
#define NUM 1
int main(int argc, char **argv) {
// This is a test comment
printf("Hello World!\n");
for(int i = 0; i < 10; ++i) {
printf("%d\n", NUM);
}
return 0;
}这次的环境是WSL的官方Arch Linux。本文参考了我本科时期CSAPP课的大作业“Hello的一生”。
硬盘到内存
我们首先来回顾一下,一个程序的物理运行过程。
粗糙来说,一个程序的运行过程要经历这样几个阶段——硬盘阶段、内存阶段和CPU阶段。
硬盘阶段
磁盘中存储的并不是什么1和0,而是高电平和低电平的信息。拿基础的磁盘来举例子,磁盘上的存储介质是磁粉,依靠磁粉颗粒的磁极指向来记录数据的。传统的机械磁盘,是由若干盘片组成的,排列成一个圆柱体的样式:
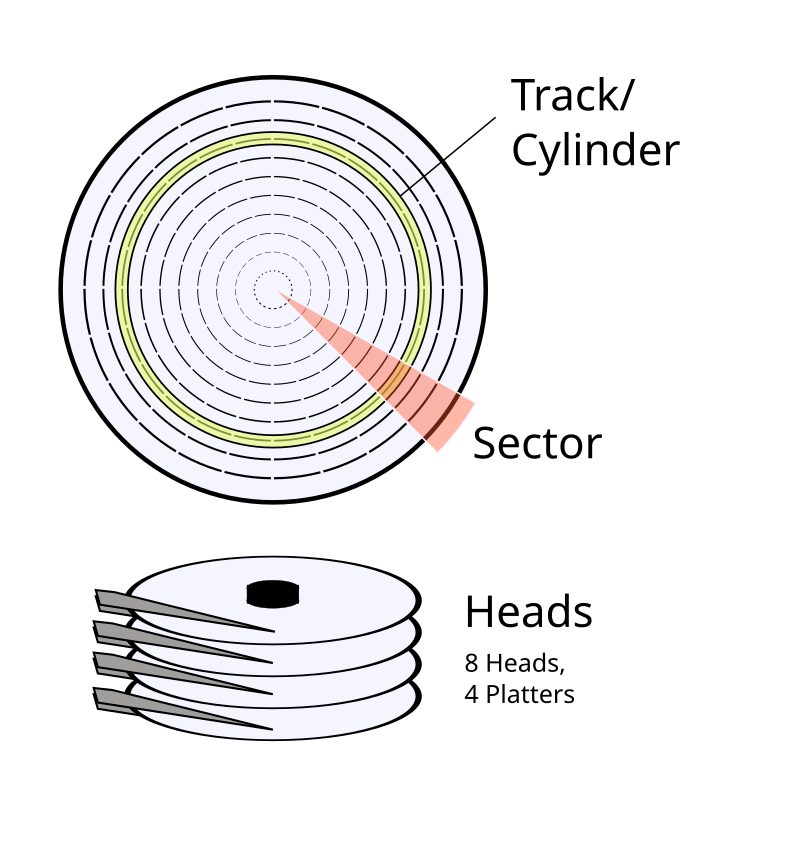
相比于内存,硬盘——或者说绝大多数大容量存储介质,如光盘等——容量更大,但是读取更慢。如果直接依靠硬盘和CPU进行交互,会导致硬盘的读取速度跟不上CPU的运行速度,拖慢整体的运行速度。
这个时候,我们就需要一个“中介”,来桥接硬盘和CPU之间的连接。要使用/即将使用的数据,就让它先被读取到内存中,然后通过内存与CPU沟通,效率很高。
读取的时候,CPU根据调用读取命令的指令,进行运算,得到信号,通过电路转化为硬盘能够理解的格式,将数据读入到内存中。
内存阶段
内存中分为若干个部分,有一些部分存储纯数据,有一部分存储指令,CPU在执行程序时,是按顺序读取指令进行执行的,内存中存储的依旧是高低电平信息,通过电路转换、输入到CPU的引脚,进行运算。
具体的内存寻址将在后续的文章中讲述——或许不会,用不到就不会写了。
CPU阶段
CPU的执行过程,分为取指、译码、执行、访存、写回五个步骤。
首先,CPU根据程序计数器(PC)向内存发送信号。PC中记录的是当前指令在内存中的的地址,当CPU将PC中的内容发送给内存时(这一步要借助MAR,不过本文隐去大多数无关痛痒的细节),内存通过数据总线将对应的值发送给CPU。这便是取指的过程。
其次,CPU要处理获取到的指令。通过电路,获取到操作数以及操作码,并生成控制信号,让CPU内部的其他部件做好准备。这便是译码。
之后,CPU要执行指令。执行指令分为三类:运算指令、访存指令和跳转指令。对于运算指令来说,CPU则将必要的信息交付给ALU,ALU根据电信号进行运算;对于访存指令来说,CPU计算出一个地址,为后续访存步骤做准备;对于跳转指令来说,则修改PC的值,回到取指。
如果要访存,则要向内存发送请求,通过若干内存管理机制——这一部分的细节略去——处理信息。
最后,要将结果写入对应的寄存器中,即为写回步骤。
现代CPU往往通过一些优化方式,进一步加快运算,比如流水线机制、超标量机制等,这里不再赘述。
编译为二进制
既然我们已经大致知道了底层的运行逻辑,那么来看一看顶层时如何运行的吧。我们写好了一个程序,存储到磁盘中,但是这是一个文本文件,我们还需要将它转化为CPU能理解的指令集,这一个过程便是编译。
预处理
编译的第一步是预处理,所需要的工具是cpp。预处理的目的是对文本格式的程序,进行基本的文本层面的处理。简单来说,这一步会处理C语言程序中所有以#开头的代码,并且删去注释。
废话少说,我们来实际操作一番。首先,我们来预处理test.c:
cpp test.c > test.i然后,我们来观察一下发生了什么:
wc -l test.i #输出:975 test.i
cat test.i通过统计行数,我们发现,文件的行数变为了975行。打开文件,我们发现文件的最后几行变为:
int main(int argc, char **argv) {
printf("Hello World!\n");
for(int i = 0; i < 10; ++i) {
printf("%d\n", 1);
}
return 0;
}很显然,#define NUM 1这一行被处理了,代码中所有出现NUM的地方,都被替换为了1。除此之外,我们的注释也被删除了。
通过文件中其它的内容,比如:
extern char *ctermid (char *__s) __attribute__ ((__nothrow__ , __leaf__))
__attribute__ ((__access__ (__write_only__, 1)));
# 931 "/usr/include/stdio.h" 3 4
extern void flockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) __attribute__ ((__nonnull__ (1)));
extern int ftrylockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) __attribute__ ((__nonnull__ (1)));
extern void funlockfile (FILE *__stream) __attribute__ ((__nothrow__ , __leaf__)) __attribute__ ((__nonnull__ (1)));
# 949 "/usr/include/stdio.h" 3 4
extern int __uflow (FILE *);
extern int __overflow (FILE *, int);
# 973 "/usr/include/stdio.h" 3 4我们可以发现,预处理对于头文件的处理实际上极其简单,就是将头文件的部分粘贴过来,做一些标记。我们看到的以#开头的部分,叫做linemarker1,从左到右依次为:行数、源文件名和标记。1表示一个文件的开始,2表示返回到某一文件,3表示后面的内容来自于系统文件,4表示后面的内容其实呈现在了一个隐性的extern "C"块里(当然,这个其实并不是很重要)。
比如,我们可以:
cat /usr/include/stdio.h | head -n 950得到的结果是:
extern int __uflow (FILE *);
extern int __overflow (FILE *, int);这也印证了我们之前所说的,有关于标记3的内容,以及行号。
我们再来尝试一个文件b.c:
#include "a.h"
int main() {
return 0;
}a.h的内容是:
#define A 3最终的预处理结果是:
# 0 "b.c"
# 0 "<built-in>"
# 0 "<command-line>"
# 1 "/usr/include/stdc-predef.h" 1 3 4
# 0 "<command-line>" 2
# 1 "b.c"
# 1 "a.h" 1
# 2 "b.c" 2
int main() {
return 0;
}我们尤其要关注最后两行linemarker,分别声明了a.h的结束和b.c的开始,这表明,预处理是按照顺序来的。
编译
编译是一个将预处理后C语言代码转化为汇编语言的过程。
我们不妨尝试:
gcc -S test.i -o test.s最后输出了这么一段结果:
.file "test.c"
.text
.section .rodata
.LC0:
.string "Hello World!"
.LC1:
.string "%d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $32, %rsp
movl %edi, -20(%rbp)
movq %rsi, -32(%rbp)
leaq .LC0(%rip), %rax
movq %rax, %rdi
call puts@PLT
jmp .L2
.L3:
leaq .LC1(%rip), %rax
movl $1, %esi
movq %rax, %rdi
movl $0, %eax
call printf@PLT
addl $1, -4(%rbp)
.L2:
cmpl $9, -4(%rbp)
jle .L3
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (GNU) 15.1.1 20250729"
.section .note.GNU-stack,"",@progbits这一段我们就触及到了CPU能理解的代码范围——汇编代码。我们一行一行慢慢解释,首先指定了编译的文件名称,然后依靠.text声明代码段的开始,存储了一些只读信息和具体要执行的代码,随后指定了.rodata段,这一段存储字符串和宏信息。值得注意的是,后面跟了两个.LC段,实际上,LC实际上是指Local Constant,存储了一些只读变量。.globl main表明main是一个全局符号,需要链接器留意,后面的.type声明了,main是一个函数2。
随后,我们进入了主函数的函数体逻辑。.cfi_startproc表明了,我们要开始处理Call Frame Information3,也就是栈帧信息,所有和cfi有关的信息,都是为了调试器而设计的,我们不做解释。随后是栈帧创建的三步,这里我们要解释rbp和rsp两个寄存器的作用,它们分别存储了BP(Base Pointer)和SP(Stack Pointer),分别存储了栈帧基址指针和栈指针,即当前函数的栈基址和栈顶地址。栈帧创建的三步分别是:
- 存储旧的栈基址。
- 用当前函数的栈基址替换旧的栈基址。
- 更新栈顶地址,分配了32字节的栈空间。
这便是主函数前三步的作用。
随后,是两个保存参数的步骤,将argc和argv保存到-20(%rbp)和-32(%rbp)的位置上。之后,是一步RIP相对寻址,利用当前指令的地址加上偏移量,能够获得全局变量的地址,亦即"Hello World!"这个字符串,随后将这个值传入rdi寄存器,这个寄存器是用于函数传参的。
随后是一个调用过程链接表(PLT)的步骤,call指令将下一条指令入栈,便于返回用,随后调用了puts函数进行输出,因为,编译器自动认为puts优于printf——因为我们的直接输出,并没有占位符。随后的PLT的目的是,因为puts不在test.c中出现,所以需要链接过程来确定地址。
随后,通过movl $0, -4(%rbp)进行循环的初始化,即i=0这一步,之后跳入.L2段,执行迭代的过程。
后面的过程就很好理解了,所谓循环,在汇编中,是依靠比较-跳转两个过程进行的,首先判断——即cmpl这一步——是否不符合迭代条件(即jle这一步),如果不符合,就跳出循环,否则就进入L3段运行。
汇编
在Linux下,汇编是表示将文件打包为ELF文件格式4的过程:
as test.s -o test.o通过readelf工具可以读取它的内容:
readelf -a test.o > test.elf首先是ELF头的内容:
ELF Header:
Magic: 7f 45 4c 46 02 01 01 00 00 00 00 00 00 00 00 00
Class: ELF64
Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V
ABI Version: 0
Type: REL (Relocatable file)
Machine: Advanced Micro Devices X86-64
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 736 (bytes into file)
Flags: 0x0
Size of this header: 64 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 64 (bytes)
Number of section headers: 14
Section header string table index: 13其中,Magic Number的前四位是0x7f,表示“ELF”,后面的02是一个flag,0表示无效ELF文件,1表示32位,2表示64位,后面的01是另一个flag,0表示无效格式,1是小端法,2是大端法,后面的01表示ELF格式。
后面一部分是节头:
Section Headers:
[Nr] Name Type Address Offset
Size EntSize Flags Link Info Align
[ 0] NULL 0000000000000000 00000000
0000000000000000 0000000000000000 0 0 0
[ 1] .text PROGBITS 0000000000000000 00000040
0000000000000051 0000000000000000 AX 0 0 1
[ 2] .rela.text RELA 0000000000000000 000001f0
0000000000000060 0000000000000018 I 11 1 8
[ 3] .data PROGBITS 0000000000000000 00000091
0000000000000000 0000000000000000 WA 0 0 1
[ 4] .bss NOBITS 0000000000000000 00000091
0000000000000000 0000000000000000 WA 0 0 1
[ 5] .rodata PROGBITS 0000000000000000 00000091
0000000000000011 0000000000000000 A 0 0 1
[ 6] .comment PROGBITS 0000000000000000 000000a2
000000000000001c 0000000000000001 MS 0 0 1
[ 7] .note.GNU-stack PROGBITS 0000000000000000 000000be
0000000000000000 0000000000000000 0 0 1
[ 8] .note.gnu.pr[...] NOTE 0000000000000000 000000c0
0000000000000030 0000000000000000 A 0 0 8
[ 9] .eh_frame PROGBITS 0000000000000000 000000f0
0000000000000038 0000000000000000 A 0 0 8
[10] .rela.eh_frame RELA 0000000000000000 00000250
0000000000000018 0000000000000018 I 11 9 8
[11] .symtab SYMTAB 0000000000000000 00000128
00000000000000a8 0000000000000018 12 4 8
[12] .strtab STRTAB 0000000000000000 000001d0
0000000000000019 0000000000000000 0 0 1
[13] .shstrtab STRTAB 0000000000000000 00000268
0000000000000074 0000000000000000 0 0 1描述了各个section的信息。
后面比较重要的信息是:
Relocation section '.rela.text' at offset 0x1f0 contains 4 entries:
Offset Info Type Sym. Value Sym. Name + Addend
000000000012 000300000002 R_X86_64_PC32 0000000000000000 .rodata - 4
00000000001a 000500000004 R_X86_64_PLT32 0000000000000000 puts - 4
00000000002a 000300000002 R_X86_64_PC32 0000000000000000 .rodata + 9
00000000003c 000600000004 R_X86_64_PLT32 0000000000000000 printf - 4这里,包含了我们之前的需要PLT的函数——puts和printf,但是,这里有一个问题,为什么出现了.rodata相关的内容?这些内容也需要重定位吗?其实这些定位的内容都是“全局符号”,如果代码被编译成动态链接库,则需要一个结构来表示这些全局符号的内容,这也叫做“基于PC的相对寻址”。
那么,我们来实际看一看这些汇编与之前那一步有什么不同吧:
objdump -d -r test.o > test.dump其内容为:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 20 sub $0x20,%rsp
8: 89 7d ec mov %edi,-0x14(%rbp)
b: 48 89 75 e0 mov %rsi,-0x20(%rbp)
f: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 16 <main+0x16>
12: R_X86_64_PC32 .rodata-0x4
16: 48 89 c7 mov %rax,%rdi
19: e8 00 00 00 00 call 1e <main+0x1e>
1a: R_X86_64_PLT32 puts-0x4
1e: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
25: eb 1d jmp 44 <main+0x44>
27: 48 8d 05 00 00 00 00 lea 0x0(%rip),%rax # 2e <main+0x2e>
2a: R_X86_64_PC32 .rodata+0x9
2e: be 01 00 00 00 mov $0x1,%esi
33: 48 89 c7 mov %rax,%rdi
36: b8 00 00 00 00 mov $0x0,%eax
3b: e8 00 00 00 00 call 40 <main+0x40>
3c: R_X86_64_PLT32 printf-0x4
40: 83 45 fc 01 addl $0x1,-0x4(%rbp)
44: 83 7d fc 09 cmpl $0x9,-0x4(%rbp)
48: 7e dd jle 27 <main+0x27>
4a: b8 00 00 00 00 mov $0x0,%eax
4f: c9 leave
50: c3 ret由于重定位的加入,我们不再需要那些section了,但是,很多内容我们还不知道,比如puts和printf到底该怎么运行?程序从哪里进入?这些我们都不知道,因为我们还没有进行链接操作。
链接
链接所使用的命令是:
ld -o test -dynamic-linker /lib64/ld-linux-x86-64.so.2 /lib64/crt1.o /lib64/crti.o test.o /lib64/libc.so /lib64/crtn.o这条命令的解释:
ld \
-o test \ # 输出可执行文件名为 test
-dynamic-linker /lib64/ld-linux-x86-64.so.2 \ # 指定动态链接器(运行时负责加载共享库)
/lib64/crt1.o \ # C 运行时启动文件(程序入口点 _start 所在)
/lib64/crti.o \ # C 运行时初始化文件(处理程序启动/终止的预备工作)
test.o \ # 用户编写的代码编译生成的目标文件
/lib64/libc.so \ # C 标准库(提供 printf、puts 等函数)
/lib64/crtn.o # C 运行时终止文件(处理程序退出的收尾工作)链接的流程是:后面的文件能为前面的文件提供解释。
利用objdump查看,结果是:
test: file format elf64-x86-64
Disassembly of section .init:
0000000000401000 <_init>:
401000: f3 0f 1e fa endbr64
401004: 48 83 ec 08 sub $0x8,%rsp
401008: 48 8b 05 d1 2f 00 00 mov 0x2fd1(%rip),%rax # 403fe0 <__gmon_start__@Base>
40100f: 48 85 c0 test %rax,%rax
401012: 74 02 je 401016 <_init+0x16>
401014: ff d0 call *%rax
401016: 48 83 c4 08 add $0x8,%rsp
40101a: c3 ret
Disassembly of section .plt:
0000000000401020 <puts@plt-0x10>:
401020: ff 35 ca 2f 00 00 push 0x2fca(%rip) # 403ff0 <_GLOBAL_OFFSET_TABLE_+0x8>
401026: ff 25 cc 2f 00 00 jmp *0x2fcc(%rip) # 403ff8 <_GLOBAL_OFFSET_TABLE_+0x10>
40102c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000401030 <puts@plt>:
401030: ff 25 ca 2f 00 00 jmp *0x2fca(%rip) # 404000 <puts@GLIBC_2.2.5>
401036: 68 00 00 00 00 push $0x0
40103b: e9 e0 ff ff ff jmp 401020 <_init+0x20>
0000000000401040 <printf@plt>:
401040: ff 25 c2 2f 00 00 jmp *0x2fc2(%rip) # 404008 <printf@GLIBC_2.2.5>
401046: 68 01 00 00 00 push $0x1
40104b: e9 d0 ff ff ff jmp 401020 <_init+0x20>
Disassembly of section .text:
0000000000401050 <_start>:
401050: f3 0f 1e fa endbr64
401054: 31 ed xor %ebp,%ebp
401056: 49 89 d1 mov %rdx,%r9
401059: 5e pop %rsi
40105a: 48 89 e2 mov %rsp,%rdx
40105d: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
401061: 50 push %rax
401062: 54 push %rsp
401063: 45 31 c0 xor %r8d,%r8d
401066: 31 c9 xor %ecx,%ecx
401068: 48 c7 c7 85 10 40 00 mov $0x401085,%rdi
40106f: ff 15 63 2f 00 00 call *0x2f63(%rip) # 403fd8 <__libc_start_main@GLIBC_2.34>
401075: f4 hlt
401076: 66 2e 0f 1f 84 00 00 cs nopw 0x0(%rax,%rax,1)
40107d: 00 00 00
0000000000401080 <_dl_relocate_static_pie>:
401080: f3 0f 1e fa endbr64
401084: c3 ret
0000000000401085 <main>:
401085: 55 push %rbp
401086: 48 89 e5 mov %rsp,%rbp
401089: 48 83 ec 20 sub $0x20,%rsp
40108d: 89 7d ec mov %edi,-0x14(%rbp)
401090: 48 89 75 e0 mov %rsi,-0x20(%rbp)
401094: 48 8d 05 69 0f 00 00 lea 0xf69(%rip),%rax # 402004 <_IO_stdin_used+0x4>
40109b: 48 89 c7 mov %rax,%rdi
40109e: e8 8d ff ff ff call 401030 <puts@plt>
4010a3: c7 45 fc 00 00 00 00 movl $0x0,-0x4(%rbp)
4010aa: eb 1d jmp 4010c9 <main+0x44>
4010ac: 48 8d 05 5e 0f 00 00 lea 0xf5e(%rip),%rax # 402011 <_IO_stdin_used+0x11>
4010b3: be 01 00 00 00 mov $0x1,%esi
4010b8: 48 89 c7 mov %rax,%rdi
4010bb: b8 00 00 00 00 mov $0x0,%eax
4010c0: e8 7b ff ff ff call 401040 <printf@plt>
4010c5: 83 45 fc 01 addl $0x1,-0x4(%rbp)
4010c9: 83 7d fc 09 cmpl $0x9,-0x4(%rbp)
4010cd: 7e dd jle 4010ac <main+0x27>
4010cf: b8 00 00 00 00 mov $0x0,%eax
4010d4: c9 leave
4010d5: c3 ret
Disassembly of section .fini:
00000000004010d8 <_fini>:
4010d8: f3 0f 1e fa endbr64
4010dc: 48 83 ec 08 sub $0x8,%rsp
4010e0: 48 83 c4 08 add $0x8,%rsp
4010e4: c3 ret增添了程序的初始入口,以及结束所用的代码,也引入了C标准库中的函数,到此,我们的程序算是能运行起来了。
后记
说实话,这篇写得有够烂的了。深究下去,这篇文章还有很多很多很多很多可以写的地方,不过,不利于我回看时学习。
其实,只需要了解程序大概运行的逻辑以及汇编语言的基础就足够了,就足以让我们去Crack一些软件了。
参考资料
- https://gcc.gnu.org/onlinedocs/cpp/Preprocessor-Output.html ↩
- https://sourceware.org/binutils/docs/as/Type.html#Type ↩
- https://sourceware.org/binutils/docs-2.31/as/CFI-directives.html ↩
- https://zh.wikipedia.org/zh-cn/%E5%8F%AF%E5%9F%B7%E8%A1%8C%E8%88%87%E5%8F%AF%E9%8F%88%E6%8E%A5%E6%A0%BC%E5%BC%8F ↩